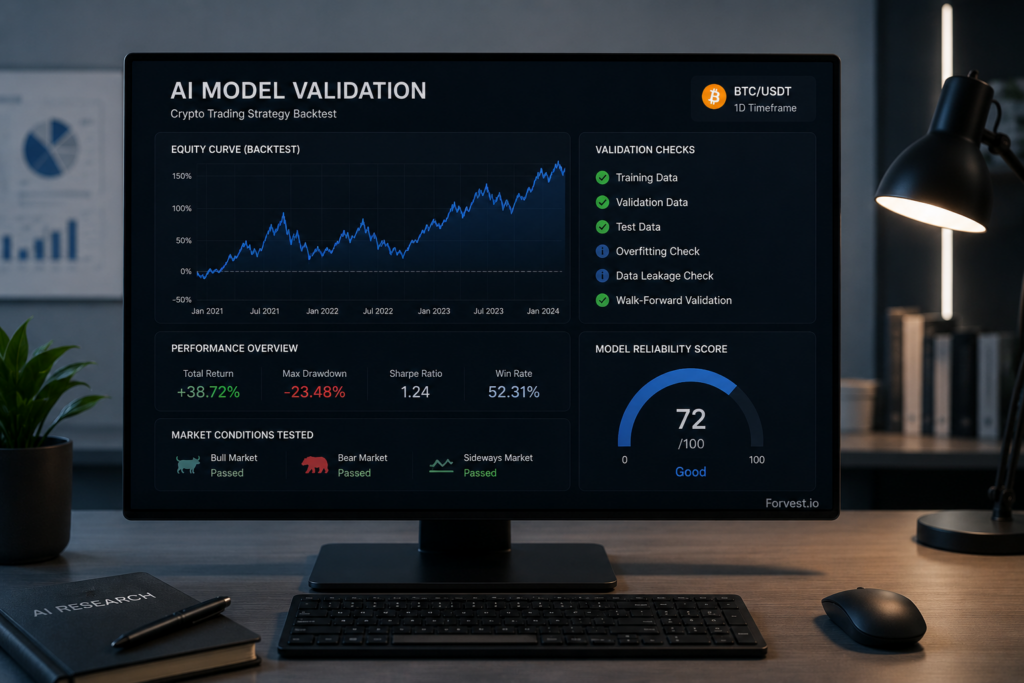
- TL;DR
- Why most backtests fail investors
- Top mistakes (and how to fix each)
- 1) Look-ahead bias
- 2) Survivorship bias
- 3) Frictions & liquidity blind spots
- 4) Parameter cliffs (curve fitting)
- 5) One-era dependence
- 6) No holdout / no walk-forward
- 7) Unrealistic execution
- Robustness checks that actually matter
- Pre-Flight QA (30-minute checklist)
- What to publish (and what not)
- From backtest to live (safely)
- Conclusion
- Related Forvest Tools in Our AI Assistant, Fortuna
Most failed crypto backtests share avoidable flaws: look-ahead and survivorship bias, friction and liquidity blind spots, parameter cliffs, and one-era overfitting. Fix them with time-based splits (Design → OOS → Holdout), walk-forward validation, and simple robustness checks so results stay honest when markets shift.
TL;DR
-
Most “amazing” backtests break due to biases, frictions/liquidity, and overfitting.
-
Build on three pillars: time-based splits, walk-forward validation, and friction-in-the-loop.
-
Choose parameter plateaus (not spikes) and run basic robustness checks before risking capital.
-
A quick Pre-Flight QA in Part 2 makes deployment decisions clear.
Why most backtests fail investors
A backtest is a decision tool, not a trophy. Traders often optimize for the prettiest equity curve; investors need durability—results that survive regime shifts, fees, slippage, and imperfect execution. When a test leaks future information, ignores tradability, or hinges on a magic parameter that only works in one era, the curve looks amazing… until you deploy it.
Good investor backtests are boringly rigorous: they separate time properly, price in frictions inside the loop, and prove the idea across windows. The goal isn’t to maximize past CAGR—it’s to minimize nasty surprises.
 Related: Want to start from the basics? See Crypto Portfolio Backtesting — The Complete Guide
Related: Want to start from the basics? See Crypto Portfolio Backtesting — The Complete Guide

Visualizing bias traps — perfect curves often hide future leaks and missing failures.
Top mistakes (and how to fix each)
1) Look-ahead bias
What it looks like
Features or filters computed with information that wasn’t available at decision time (e.g., endpoint-dependent indicators, future-aware labels).
Why it hurts
You’re borrowing tomorrow’s certainty to “predict” yesterday. Live results won’t have that privilege.
Fix
-
Lock time indices; compute all features from strictly past data.
-
Rebuild the historical data pipeline exactly as it would have run.
-
Use chronological splits only (no shuffling across eras).
2) Survivorship bias
What it looks like
Testing on today’s survivors only; delisted/failed projects vanish from history.
Why it hurts
Inflates returns and understates drawdowns, especially in alt cycles.
Fix
-
Use a complete historical universe (including dead/delisted).
-
Apply liquidity/market-cap filters per window (not fixed lists).
-
Document excluded assets and reasons.
3) Frictions & liquidity blind spots
What it looks like
Ignoring commissions, spreads, slippage, and venue depth—or applying them after the fact.
Why it hurts
Costs compound; thin books move price against you. High turnover can erase paper edges.
Fix
-
Model fees + slippage inside the loop (per trade).
-
Enforce min volume/market-cap per window; cap turnover.
-
Stress costs at 1.5–2× to see if the edge survives.

Choose stability over perfection — plateaus survive, spikes break.
4) Parameter cliffs (curve fitting)
What it looks like
The system “works” only at a razor-thin setting (e.g., 127-day lookback is magical; 120 or 130 break it).
Why it hurts
Cliffs signal you fit noise; small live differences flip outcomes.
Fix
-
Prefer plateaus—choose parameters from a broad stable region.
-
Keep rules simple; avoid chains of thresholds.
-
Validate stability with rolling windows and mild noise tests.
5) One-era dependence
What it looks like
Shines in a bull (e.g., 2020–2021); bleeds in 2022 bear or sideways chop.
Why it hurts
Live markets rotate regimes. A single-phase hero won’t survive a full cycle.
Fix
-
Slice results by bull/bear/sideways; name the weak phase openly.
-
Add regime filters or slower cadence in chop; constrain exposure in bear.
-
Require the strategy’s personality to remain recognizable across slices.
6) No holdout / no walk-forward
What it looks like
Optimizing on one span and reporting the same span; or “peeking” and retuning repeatedly.
Why it hurts
You don’t know if the idea generalizes. Retuning after seeing results is hindsight dressed up.
Fix
-
Split by time: Design (IS) → Validation (OOS-1) → Holdout (OOS-2).
-
Touch Holdout once at the very end.
-
Add walk-forward: sequential train-then-test windows stitched into one equity curve.
Related: Learn more about Types of Investment Backtests: Historical, Walk-Forward & Live
7) Unrealistic execution
What it looks like
Assuming perfect fills at close, no latency, never missing a rebalance, and unlimited capacity in thin alts.
Why it hurts
Real portfolios miss trades, slip by minutes/days, or partially fill. Paper edges vanish under friction and disorder.
Fix
-
Add timing drift (±1–2 days) and missed-action tests (~10% skips).
-
Use path dispersion (Monte Carlo resampling) to see outcome spread.
-
Start live with small size and confirm fills/latency match assumptions.
Time-based split that matches investor reality
Backtests must respect time. Use chronological splits so you never “learn” from the future and you can judge generalization fairly.
Table — Time-based split that matches investor reality
| Phase | Share of history | Purpose | Rules |
|---|---|---|---|
| Design (In-Sample) | ~60–70% earliest | Build simple, explainable logic | Limit variants; avoid complexity creep |
| Validation (OOS-1) | ~15–20% next | Test only shortlisted variants | No retuning after seeing results |
| Holdout (OOS-2) | ~15–20% last | One-time final exam | Touch once; confirm generalization |
How to read it: Similar character between Design and OOS-1 is a good sign; graceful (not catastrophic) degradation in Holdout suggests real signal. If results collapse when you move forward in time, the edge is likely overfit.
Robustness checks that actually matter
Once you have a “good” result, try to break it on purpose. If it survives these tests, you probably have something real.
Table — Robustness Stress-Test Checklist
| Category | Test | What you do | What you want to see |
|---|---|---|---|
| Friction | Cost stress | 1.5–2× fees & slippage | Character survives; not a thesis flip |
| Data | Noise injection | ±0.5–1.0% price jitter on rebalance | Rankings stable; metrics degrade gracefully |
| Timing | Drift test | Shift rebalance by ±1–2 days | No regime personality swap; similar DD ceiling |
| Liquidity | Tradability filter | Enforce min volume/cap per window | Returns stay believable; turnover drops if needed |
| Path | Monte Carlo | Resample day/order; view dispersion | Middle of distribution still investable |
| Execution | Missed actions | Randomly skip ~10% rebalances | No collapse; slightly lower but intact profile |
| Regime | Sliced tests | Bull / bear / sideways subsets | Known weak phase but bounded pain |
Pre-Flight QA (30-minute checklist)
-
Chronological splits in place (Design → OOS-1 → Holdout), covering at least one bull and one bear.
-
Friction-in-the-loop (fees, slippage, and basic liquidity constraints modeled per trade).
-
Parameter plateau chosen (not a single spike); rules remain simple and explainable.
-
Walk-forward run with 3–4 rolling windows; stitched equity shows consistent personality.
-
Cost stress at 1.5–2× does not flip the thesis.
-
Timing drift (±1–2 days) and missed-action tests do not collapse results.
-
Noise injection (mild price jitter) degrades gracefully; rankings largely stable.
-
Regime slices reviewed (bull/bear/sideways); weak phase is known and bounded.
-
Liquidity filter applied per window; turnover is economically sensible.
-
Optimization report completed (objective, splits, settings, metrics, robustness notes, decision).
What to publish (and what not)
Publish:
-
Clear objective (e.g., balance return vs. drawdown) and cadence (weekly/monthly).
-
Splits (Design/OOS/Holdout) and a short walk-forward summary.
-
Core metrics: CAGR, Max DD, Sharpe/Calmar, worst year/month, time under water, turnover.
-
Short regime profile (how it behaved in bull/bear/sideways).
-
One paragraph on frictions & liquidity assumptions.
-
One paragraph on known risks/limits (where it struggles).
Avoid:
-
Cherry-picked subperiods without disclosure.
-
Hyper-precise “magic” parameters with no stability evidence.
-
Unrealistic execution assumptions (perfect fills, unlimited capacity).
From backtest to live (safely)
-
Paper first (or tiny-live). Track fills, latency, and slippage vs. assumptions.
-
Automate alerts. Translate your thresholds/bands into simple price alerts so you execute your plan, not emotion.
-
Scale gradually. Increase size only after paper/tiny-live behavior matches expectations.
-
Review on cadence. Recheck robustness quarterly or when regimes shift; avoid constant retuning.
-
Document changes. Version parameters and keep a short change log.
Conclusion
Reliable backtesting is about evidence, not aesthetics. Respect time, select parameters from plateaus, and pressure-test the idea with costs, timing, noise, liquidity, execution, and regime slices. If the strategy’s character holds together after all that, you’ve earned the right to take it live—carefully.
Related Forvest Tools in Our AI Assistant, Fortuna
Forvest Trust Score helps investors evaluate crypto projects based on real transparency and reliability metrics. It identifies trustworthy assets and highlights hidden risks, guiding you toward safer investment decisions.
Forvest Alerts keeps you informed about key market movements and sentiment shifts — not just prices, but also major news that may impact your portfolio — helping you stay proactive instead of reactive.
— Forvest Research